
Connect Four AI Using Reinforcement Learning
📅 Mar. 2020 - Jun. 2020 • 📄 Report • ![]() Github
Github
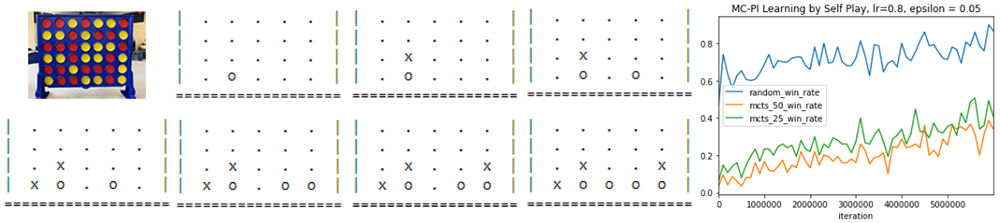
This project studies two reinforcement learning algorithms: Q-learning and Monte-Carlo policy iteration. These techniques are applied to a two-player game called Connect Four, which is a game similar to tic-tac-toe, in order to learn a policy which will allow an AI agent to play the game at a high level. The game is formally described as a Markv decision process (MDP), and the RL algorithms are applied to it. This includes the generation of episodes using self-play, used to update the policy. The final results are presented qualitatively and quantitatively on a variety of different opponents. Insight is also given into the effect of various parameters, finishing with recommendation on which are the most beneficial. For details, please refer to the report.
