
Self-Driving Cars using 2D/3D Action and Explanation Prediction
📅 Feb. 2021 - May 2022
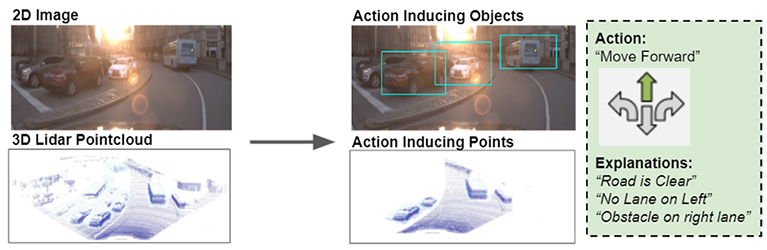
A currently ongoing project, where I am guiding the formulation and development of a new neural network model for autonomous vehicle navigation. Both 2D images and 3D pointclouds are utilized through multimodal fusion, to predict actions (such as move foward, turn left, etc). Unlike other methods in the literature however, we also predict intuitive explanations for these actions (such as “clear road” or “blocking object: pedestrian”). Furthermore, 2D and 3D detected bounding boxes (from Faster R-CNN and MVX-Net) are also provided to indicate specific action-induced objects in 2D and 3D. Annotations on Amazon Mechanical Turk are also currently being collected for action and explanation labels, to add to the Waymo Open dataset.
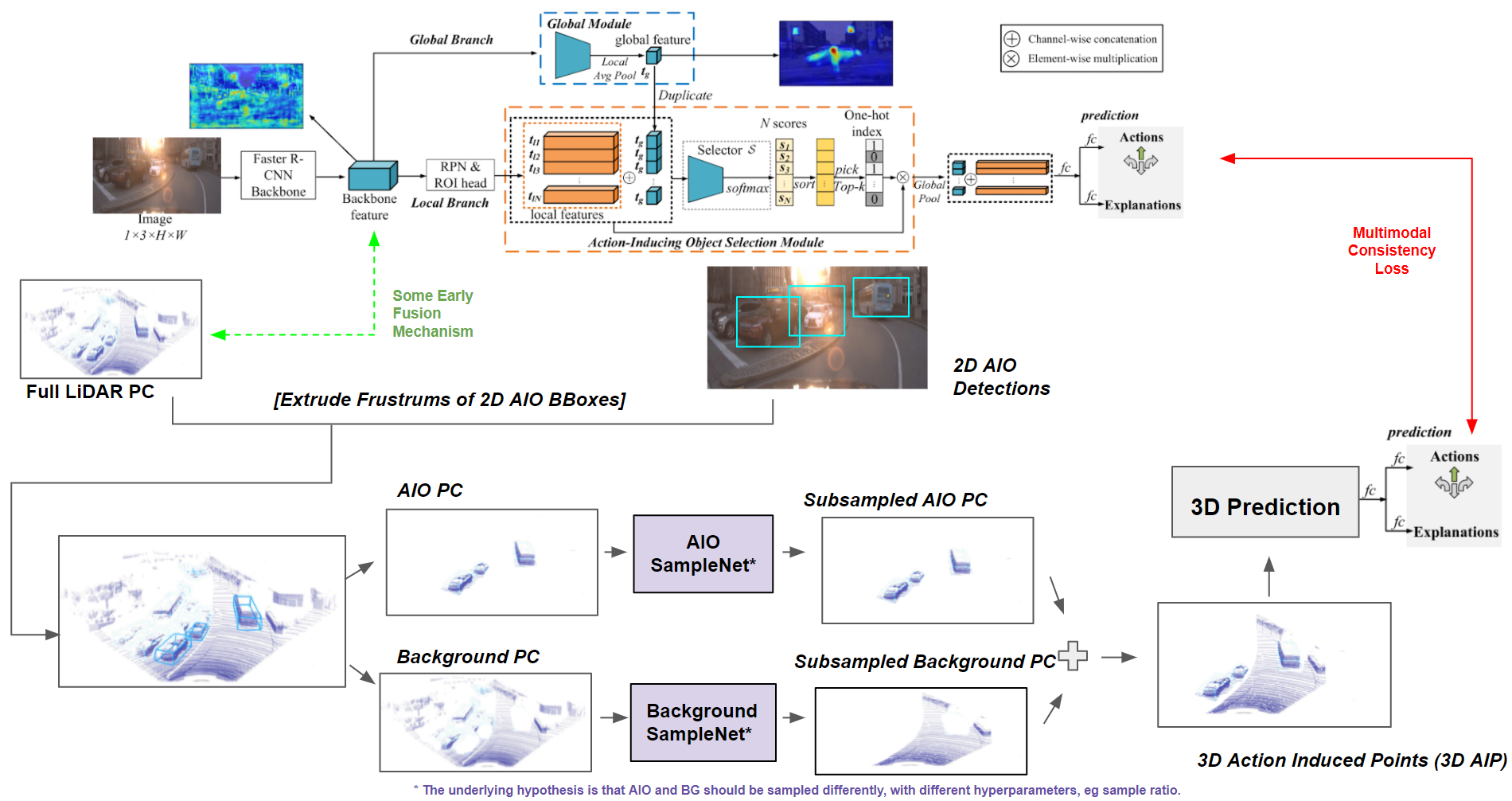
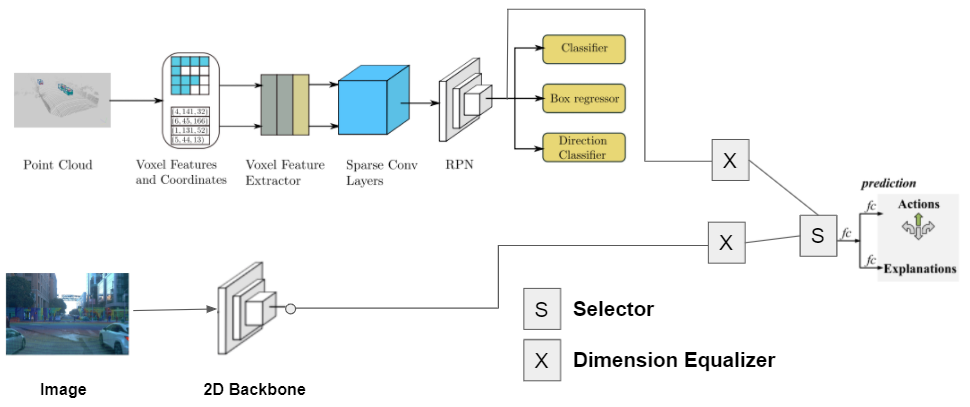
Other collaborators on this project: Arth Dharaskar, Allen Cheung, Chih-Hui Ho, Tz-Ying Wu.